My first speedy forecast
Short description of the SPEEDY model
SPEEDY is an atmospheric global circulation model that uses the spectral dynamical core developed at the Geophysical Fluid Dynamics Laboratory. Its main characteristics are: - A spectral-transform model in the vorticity-divergence form with a semi-implicit treatment of gravity waves. - Hydrostatic σ-coordinate in the vertical coordinate. - The principal model prognostic variables are vorticity, divergence, temperature, and the logarithm of surface pressure. - Humidity is advected by the dynamical core, and with its sources and sinks are determined physical parametrizations. - The horizontal resolution corresponds to a triangular spectral truncation at total wavenumber 30 (T30, approximately 3.75 x 3.75 degree resolution). This corresponds to a Gaussian grid of 96 (longitude) by 48 (latitude) points. - For the vertical coordinate, eight levels are used with boundaries at σ values of 0, 0.05, 0.14, 0.26, 0.42, 0.60, 0.77, 0.90 and 1. The prognostic variables (except log(ps)) are specified at the σ levels in between the latter boundaries, namely at σ 0.025, 0.095, 0.20, 0.34, 0.51, 0.685, 0.835 and 0.9 - Time step: 40min. That is, 36 time steps per day.
For additional details, check the SPEEDY documentation here.
The boundary conditions
The boundary conditions needed to run SPEEDY are:
Time invariant fields (lon, lat):
orog: Orographic height [m]
lsm: Land sea mask fraction. Values between 0 and 1.
vegl: Low vegetation cover (fraction). Values between 0 and 1.
vegh: High vegetation cover (fraction). Values between 0 and 1.
alb: Annual-mean albedo (fraction). Values between 0 and 1.
Monthly-average climatological fiel for each month of the year (lon, lat, month):
stl: Land surface temp (top-layer) [degK].
snowd: Snow depth [kg/m2]
swl1: Soil wetness (layer 1) [vol. fraction, 0-1]
swl2: Soil wetness (layer 2) [vol. fraction, 0-1]
swl3: Soil wetness (layer 3) [vol. fraction, 0-1]
icec: Sea-ice concentration (fraction). Values between 0 and 1.
sst: Sea surface temperature [degK].
Anomaly fields (lon, lat, day):
ssta: Sea surface temperature anomaly [degK].
The exact shapes for the invariant fields are (lon, lat, month) = (96, 48, 12). In contrast, the anomaly field (SST anomaly) needs to be provided for each day of the simulation period. For example, for a one-month forecast (30 days), the shape of the anomaly field is (96, 48, 30).
By default, the pySPEEDY package includes the example boundary conditions initially included in the SPEEDY.f90 package. These fields were derived from the ERA-interim re-analysis using the 1979-2008 period. In addition, the default boundary conditions include the monthly SST anomalies for the 1979-01-01 to 2013-12-01 period.
The initial conditions
The current version of pySPEEDY initializes all spectral variables at a reference atmosphere at rest with the following properties: Troposphere: T = 288°K at the surface. Constant temperature lapse rate. Stratosphere: T = 216 °K, lapse rate = 0. Pressure field consistent with the temperature field. Humidity: qv = RHref * q_saturation(288K, 1013hPa) with RHref=0.7. For this initialization, the following spectral variables are initialized: - “vor [mx, nx, levels, 2]”: Vorticity in the spectral space. Complex. - “div [mx, nx, levels, 2]”: Divergence in the spectral space. Complex. - “t [mx, nx, levels, 2]”: Temperature in the spectral space. Complex. - “ps [mx, nx, 2]”: Log of (normalised) surface pressure. - “phi [mx, nx, levels]”: Atmospheric geopotential. Real. - “phis [mx, nx]”: Surface geopotential. Real. - “tr [mx, nx, levels, 2, ntr]”: Tracers. Currently, it only contains humidity. Real.
where mx=31, nx=32, levels=8, ntr=1 (number of tracers). The “2” in the last dimension indicates that the variable is complex (0-real/1-imaginary).
Google colab fix
IMPORTANT
If you are running this notebook in Google Colab, uncomment and execute the following lines to install pySPEEDY and its dependencies.
[1]:
# !apt-get install libproj-dev proj-data proj-bin
# !apt-get install libgeos-dev libnetcdf-dev libnetcdff-dev
# !pip uninstall --yes shapely
# !pip install shapely --no-binary shapely
# !pip install cartopy
Temporary fix for https://github.com/SciTools/cartopy/issues/1869 proposed by @rcomer
[2]:
# !wget https://raw.githubusercontent.com/SciTools/cartopy/master/tools/cartopy_feature_download.py
# !python cartopy_feature_download.py physical
Now we install pySPEEDY
[3]:
#!pip install -v git+https://github.com/aperezhortal/pySPEEDY.git
End of Colab setup.
My first forecast
Let’s run our first forecast. In the following example we will run the forecast for 3 months starting from a rest atmosphere. The first month will be considered as the model spinup period over which the model outputs are not saved.
[4]:
%%time
from datetime import datetime
from pyspeedy import Speedy
from pyspeedy.callbacks import ModelCheckpoint, XarrayExporter
start_date = datetime(1980, 1, 1) # Simulation start date (datetime object).
end_date = datetime(1980, 2, 29) # Simulation end date.
spinup_date = datetime(1980, 2, 1) # End of spinup period.
# Create an instance of the speedy model.
model = Speedy(
start_date=start_date, # Simulation start date (datetime object).
end_date=end_date, # Simulation end date.
diag_interval=180, # Every how many time steps we will compute the diagnostics.
)
# At this point, the model state is "empty".
# To initialize the model, we need to define its boundary conditions first.
# This function will set the default boundary conditions derived from the ERA reanalysis.
model.set_bc()
# Before running the model, let's initialize two callback functions that
# Initialize the callback functions that saves the model data into netcdf files
# A "callback" is an object that performs user defined actions at each time step.
my_exporter = XarrayExporter(
output_dir="./data", # Output directory where the model output will be stored
interval=36, # Every how many time steps we will save the output file. 36 -> once per day.
verbose=True, # Prind progress messages
variables=None, # Which variables to output. If none, save the most commonly used variables.
spinup_date=spinup_date, # End of spinup period
)
# Let's initialized another callback. This one keeps a dataframe with selected variables
# with different model times ("checkpoints").
# The dataframe with the data is stored in the "dataframe" attribute of the
# create ModelCheckpoint instance.
model_checkpoints = ModelCheckpoint(
interval=36, # Every how many time steps we will save the output file. 36 -> once per day.
verbose=True, # Prind progress messages
variables=None, # Which variables to output. If none, save the most commonly used variables.
spinup_date=spinup_date, # End of spinup period
)
# Print the names of output variables that will be saved.
# Note that the variables shown next are in the grid space (not the spectral space)
print("Exported variables:")
print(my_exporter.variables)
# Run the model. We pass the a list of callbacks
model.run(callbacks=[my_exporter, model_checkpoints])
# After the model is run, the model state will keep the last values of the last integration step.
Exported variables:
('u_grid', 'v_grid', 't_grid', 'q_grid', 'phi_grid', 'ps_grid')
Saving model output at: ./data/1980-02-01_0000.nc.
Saving model output at: ./data/1980-02-02_0000.nc.
Saving model output at: ./data/1980-02-03_0000.nc.
Saving model output at: ./data/1980-02-04_0000.nc.
Saving model output at: ./data/1980-02-05_0000.nc.
Saving model output at: ./data/1980-02-06_0000.nc.
Saving model output at: ./data/1980-02-07_0000.nc.
Saving model output at: ./data/1980-02-08_0000.nc.
Saving model output at: ./data/1980-02-09_0000.nc.
Saving model output at: ./data/1980-02-10_0000.nc.
Saving model output at: ./data/1980-02-11_0000.nc.
Saving model output at: ./data/1980-02-12_0000.nc.
Saving model output at: ./data/1980-02-13_0000.nc.
Saving model output at: ./data/1980-02-14_0000.nc.
Saving model output at: ./data/1980-02-15_0000.nc.
Saving model output at: ./data/1980-02-16_0000.nc.
Saving model output at: ./data/1980-02-17_0000.nc.
Saving model output at: ./data/1980-02-18_0000.nc.
Saving model output at: ./data/1980-02-19_0000.nc.
Saving model output at: ./data/1980-02-20_0000.nc.
Saving model output at: ./data/1980-02-21_0000.nc.
Saving model output at: ./data/1980-02-22_0000.nc.
Saving model output at: ./data/1980-02-23_0000.nc.
Saving model output at: ./data/1980-02-24_0000.nc.
Saving model output at: ./data/1980-02-25_0000.nc.
Saving model output at: ./data/1980-02-26_0000.nc.
Saving model output at: ./data/1980-02-27_0000.nc.
Saving model output at: ./data/1980-02-28_0000.nc.
Saving model output at: ./data/1980-02-29_0000.nc.
CPU times: user 44.5 s, sys: 328 ms, total: 44.8 s
Wall time: 44.7 s
The time series of the selected variables are stored in a dataframe inside the model_checkpoints object that we pass as a callback to the model run.
[5]:
# Check the stored dataframe in the model checkout callback.
model_checkpoints.dataframe
[5]:
<xarray.Dataset>
Dimensions: (time: 29, lev: 8, lat: 48, lon: 96)
Coordinates:
* time (time) datetime64[ns] 1980-02-01 1980-02-02 ... 1980-02-29
* lev (lev) float32 0.95 0.835 0.685 0.51 0.34 0.2 0.095 0.025
* lon (lon) float32 0.0 3.75 7.5 11.25 15.0 ... 345.0 348.8 352.5 356.2
* lat (lat) float32 -87.22 -83.51 -79.79 -76.08 ... 79.79 83.51 87.22
Data variables:
u (time, lev, lat, lon) float32 -1.161 -0.8675 -0.572 ... 2.781 2.537
v (time, lev, lat, lon) float32 -3.48 -3.515 -3.519 ... -5.552 -5.649
t (time, lev, lat, lon) float32 247.6 247.2 246.9 ... 192.4 192.3
q (time, lev, lat, lon) float32 0.0003778 0.0003718 ... 0.0 0.0
phi (time, lev, lat, lon) float32 3.119e+03 3.176e+03 ... 2.304e+04
ps (time, lat, lon) float32 7.234e+04 7.178e+04 ... 1.023e+05- time: 29
- lev: 8
- lat: 48
- lon: 96
- time(time)datetime64[ns]1980-02-01 ... 1980-02-29
- axis :
- T
- standard_name :
- time
array(['1980-02-01T00:00:00.000000000', '1980-02-02T00:00:00.000000000', '1980-02-03T00:00:00.000000000', '1980-02-04T00:00:00.000000000', '1980-02-05T00:00:00.000000000', '1980-02-06T00:00:00.000000000', '1980-02-07T00:00:00.000000000', '1980-02-08T00:00:00.000000000', '1980-02-09T00:00:00.000000000', '1980-02-10T00:00:00.000000000', '1980-02-11T00:00:00.000000000', '1980-02-12T00:00:00.000000000', '1980-02-13T00:00:00.000000000', '1980-02-14T00:00:00.000000000', '1980-02-15T00:00:00.000000000', '1980-02-16T00:00:00.000000000', '1980-02-17T00:00:00.000000000', '1980-02-18T00:00:00.000000000', '1980-02-19T00:00:00.000000000', '1980-02-20T00:00:00.000000000', '1980-02-21T00:00:00.000000000', '1980-02-22T00:00:00.000000000', '1980-02-23T00:00:00.000000000', '1980-02-24T00:00:00.000000000', '1980-02-25T00:00:00.000000000', '1980-02-26T00:00:00.000000000', '1980-02-27T00:00:00.000000000', '1980-02-28T00:00:00.000000000', '1980-02-29T00:00:00.000000000'], dtype='datetime64[ns]') - lev(lev)float320.95 0.835 0.685 ... 0.095 0.025
- long_name :
- Vertical sigma coordinate
- standard_name :
- lev
array([0.95 , 0.835, 0.685, 0.51 , 0.34 , 0.2 , 0.095, 0.025], dtype=float32)
- lon(lon)float320.0 3.75 7.5 ... 348.8 352.5 356.2
- units :
- degrees_east
- long_name :
- longitude
- standard_name :
- lon
- axis :
- X
array([ 0. , 3.75, 7.5 , 11.25, 15. , 18.75, 22.5 , 26.25, 30. , 33.75, 37.5 , 41.25, 45. , 48.75, 52.5 , 56.25, 60. , 63.75, 67.5 , 71.25, 75. , 78.75, 82.5 , 86.25, 90. , 93.75, 97.5 , 101.25, 105. , 108.75, 112.5 , 116.25, 120. , 123.75, 127.5 , 131.25, 135. , 138.75, 142.5 , 146.25, 150. , 153.75, 157.5 , 161.25, 165. , 168.75, 172.5 , 176.25, 180. , 183.75, 187.5 , 191.25, 195. , 198.75, 202.5 , 206.25, 210. , 213.75, 217.5 , 221.25, 225. , 228.75, 232.5 , 236.25, 240. , 243.75, 247.5 , 251.25, 255. , 258.75, 262.5 , 266.25, 270. , 273.75, 277.5 , 281.25, 285. , 288.75, 292.5 , 296.25, 300. , 303.75, 307.5 , 311.25, 315. , 318.75, 322.5 , 326.25, 330. , 333.75, 337.5 , 341.25, 345. , 348.75, 352.5 , 356.25], dtype=float32) - lat(lat)float32-87.22 -83.51 ... 83.51 87.22
- units :
- degrees_north
- long_name :
- latitude
- standard_name :
- lat
- axis :
- Y
array([-87.216515, -83.50514 , -79.79381 , -76.08247 , -72.37113 , -68.6598 , -64.94845 , -61.23711 , -57.525764, -53.81443 , -50.10309 , -46.39175 , -42.680412, -38.969067, -35.25773 , -31.546385, -27.835052, -24.123709, -20.412367, -16.70103 , -12.989685, -9.278345, -5.567005, -1.855664, 1.855664, 5.567005, 9.278345, 12.989685, 16.70103 , 20.412367, 24.123709, 27.835052, 31.546385, 35.25773 , 38.969067, 42.680412, 46.39175 , 50.10309 , 53.81443 , 57.525764, 61.23711 , 64.94845 , 68.6598 , 72.37113 , 76.08247 , 79.79381 , 83.50514 , 87.216515], dtype=float32)
- u(time, lev, lat, lon)float32-1.161 -0.8675 ... 2.781 2.537
- units :
- m/s
- long_name :
- eastward_wind
- standard_name :
- u_grid
array([[[[-1.16051531e+00, -8.67509007e-01, -5.71996748e-01, ..., -1.98885763e+00, -1.72478759e+00, -1.44747913e+00], [-2.41950735e-01, 1.13905482e-01, 4.35540497e-01, ..., -1.40521276e+00, -1.01432955e+00, -6.22058749e-01], [ 1.15658295e+00, 1.50357199e+00, 1.75921416e+00, ..., -2.29701072e-01, 2.61729538e-01, 7.34263837e-01], ..., [-5.21863556e+00, -5.76614475e+00, -6.08784819e+00, ..., -2.25866365e+00, -3.43897033e+00, -4.43836641e+00], [-4.60856390e+00, -5.04345131e+00, -5.36138582e+00, ..., -2.78758073e+00, -3.45516706e+00, -4.07172441e+00], [-4.03680325e+00, -4.03726387e+00, -4.00631523e+00, ..., -3.88529634e+00, -3.95640039e+00, -4.00845337e+00]], [[ 1.29339665e-01, 2.80498296e-01, 4.29076999e-01, ..., -3.17224652e-01, -1.71821922e-01, -2.21969672e-02], [ 1.04226851e+00, 1.26427567e+00, 1.45790315e+00, ..., 2.74936825e-01, 5.39194286e-01, 7.97982991e-01], [ 2.44669938e+00, 2.64727497e+00, 2.76142550e+00, ..., 1.42866981e+00, 1.81898057e+00, 2.16566467e+00], ... 6.02866507e+00, 6.65437889e+00, 7.24049950e+00], [ 6.13609076e+00, 6.54016876e+00, 6.86493444e+00, ..., 4.58475304e+00, 5.14254570e+00, 5.66521883e+00], [ 6.24816942e+00, 6.43481112e+00, 6.57658911e+00, ..., 5.46127701e+00, 5.75677586e+00, 6.02067041e+00]], [[ 3.65458441e+00, 3.33976293e+00, 3.01371741e+00, ..., 4.52137566e+00, 4.24617672e+00, 3.95702577e+00], [ 6.63695478e+00, 6.43905449e+00, 6.22054052e+00, ..., 7.09189463e+00, 6.96416903e+00, 6.81238556e+00], [ 7.75579405e+00, 7.68461084e+00, 7.60239267e+00, ..., 7.86527443e+00, 7.84926033e+00, 7.81190014e+00], ..., [ 1.66420269e+01, 1.65123978e+01, 1.62232761e+01, ..., 1.61184425e+01, 1.64349632e+01, 1.66138573e+01], [ 9.57606888e+00, 9.44394588e+00, 9.20953274e+00, ..., 9.41865921e+00, 9.55402279e+00, 9.61018276e+00], [ 2.27007723e+00, 1.97853816e+00, 1.66081953e+00, ..., 3.00582957e+00, 2.78116536e+00, 2.53688145e+00]]]], dtype=float32) - v(time, lev, lat, lon)float32-3.48 -3.515 ... -5.552 -5.649
- units :
- m/s
- long_name :
- northward_wind
- standard_name :
- v_grid
array([[[[-3.47984934e+00, -3.51515126e+00, -3.51885033e+00, ..., -3.18915653e+00, -3.31577063e+00, -3.41313124e+00], [-4.20039129e+00, -4.11000443e+00, -3.95308399e+00, ..., -4.00679016e+00, -4.15259027e+00, -4.21637869e+00], [-4.19306755e+00, -3.85021472e+00, -3.43738866e+00, ..., -4.50422859e+00, -4.54304361e+00, -4.43319178e+00], ..., [-3.26081014e+00, -2.19481063e+00, -1.03748584e+00, ..., -5.21770573e+00, -4.84012699e+00, -4.16616106e+00], [-1.06179094e+00, -4.69517022e-01, 1.98432580e-01, ..., -2.13247561e+00, -1.91338801e+00, -1.55085611e+00], [ 1.35767186e+00, 1.67153513e+00, 1.99565315e+00, ..., 5.12727320e-01, 7.75665939e-01, 1.05801654e+00]], [[-1.76858759e+00, -1.75184155e+00, -1.71784890e+00, ..., -1.71404254e+00, -1.74945498e+00, -1.76777697e+00], [-2.15923500e+00, -2.05604339e+00, -1.91994882e+00, ..., -2.21939945e+00, -2.24453330e+00, -2.22358441e+00], [-1.65187657e+00, -1.35331595e+00, -1.03531396e+00, ..., -2.18363857e+00, -2.08781171e+00, -1.90462124e+00], ... 5.92776394e+00, 5.49419117e+00, 4.87088966e+00], [ 3.01347613e+00, 2.32611108e+00, 1.56815481e+00, ..., 4.53423738e+00, 4.12607527e+00, 3.61692810e+00], [ 1.47531486e+00, 9.40831363e-01, 3.81485671e-01, ..., 2.89105368e+00, 2.45356607e+00, 1.98073125e+00]], [[ 5.31830740e+00, 5.41887522e+00, 5.49832487e+00, ..., 4.90650177e+00, 5.06040144e+00, 5.19824791e+00], [ 4.49248552e+00, 4.67954302e+00, 4.84325314e+00, ..., 3.84038162e+00, 4.06773376e+00, 4.28685188e+00], [ 3.49397445e+00, 3.70995665e+00, 3.89901400e+00, ..., 2.75069308e+00, 3.00617957e+00, 3.25689507e+00], ..., [-2.97088408e+00, -4.09298182e+00, -5.22491693e+00, ..., -4.84858900e-02, -9.09187853e-01, -1.89643764e+00], [-3.94515562e+00, -4.52488041e+00, -5.11998701e+00, ..., -2.49010634e+00, -2.90975904e+00, -3.40049553e+00], [-5.74871922e+00, -5.84555387e+00, -5.93524265e+00, ..., -5.45902252e+00, -5.55156946e+00, -5.64933538e+00]]]], dtype=float32) - t(time, lev, lat, lon)float32247.6 247.2 246.9 ... 192.4 192.3
- units :
- K
- long_name :
- air_temperature
- standard_name :
- t_grid
array([[[[247.61992, 247.24971, 246.87465, ..., 248.67705, 248.336 , 247.98283], [251.4287 , 250.55528, 249.71579, ..., 254.13554, 253.23325, 252.32573], [250.80081, 249.41864, 248.20978, ..., 255.72078, 253.99258, 252.33684], ..., [259.47372, 260.47253, 261.1618 , ..., 254.71178, 256.5619 , 258.1637 ], [254.191 , 254.69122, 255.06778, ..., 252.06288, 252.8599 , 253.57579], [250.1848 , 250.28139, 250.35695, ..., 249.78583, 249.93495, 250.0687 ]], [[244.52243, 244.16438, 243.80516, ..., 245.56633, 245.22575, 244.877 ], [247.59404, 246.76381, 245.97546, ..., 250.22865, 249.33977, 248.45674], [247.00458, 245.69675, 244.55269, ..., 251.6493 , 250.01851, 248.45595], ... [202.3352 , 202.18164, 201.98306, ..., 202.44383, 202.46848, 202.4327 ], [201.76874, 201.68028, 201.58199, ..., 201.9704 , 201.91287, 201.84619], [202.21045, 202.15962, 202.11092, ..., 202.37436, 202.3179 , 202.26324]], [[221.21494, 221.33163, 221.44893, ..., 220.87633, 220.98651, 221.09962], [220.37129, 220.64677, 220.91513, ..., 219.54022, 219.81383, 220.0923 ], [220.36557, 220.7709 , 221.1453 , ..., 219.04782, 219.4938 , 219.93674], ..., [194.10878, 193.83517, 193.54881, ..., 194.78488, 194.59016, 194.36275], [192.6046 , 192.43887, 192.26915, ..., 193.05876, 192.91612, 192.76427], [192.23506, 192.16803, 192.10352, ..., 192.44823, 192.37543, 192.30429]]]], dtype=float32) - q(time, lev, lat, lon)float320.0003778 0.0003718 ... 0.0 0.0
- long_name :
- specific_humidity
- standard_name :
- q_grid
array([[[[ 3.77787626e-04, 3.71826492e-04, 3.65907210e-04, ..., 3.95508687e-04, 3.89675959e-04, 3.83752253e-04], [ 5.47616160e-04, 5.14308224e-04, 4.84132004e-04, ..., 6.63547020e-04, 6.22773718e-04, 5.83906251e-04], [ 4.89328755e-04, 3.92884365e-04, 3.10906413e-04, ..., 8.55839695e-04, 7.23101955e-04, 5.99943683e-04], ..., [ 1.12475338e-03, 1.27771194e-03, 1.39544031e-03, ..., 5.12732542e-04, 7.34624336e-04, 9.41452337e-04], [ 6.12732023e-04, 6.71832357e-04, 7.18351046e-04, ..., 3.79896228e-04, 4.64240526e-04, 5.42770838e-04], [ 4.07173939e-04, 4.17891773e-04, 4.27112158e-04, ..., 3.67914676e-04, 3.81961436e-04, 3.95127776e-04]], [[ 3.82972677e-04, 3.74543277e-04, 3.66229098e-04, ..., 4.08526743e-04, 4.00014862e-04, 3.91478708e-04], [ 4.93426283e-04, 4.66944213e-04, 4.43276513e-04, ..., 5.89876552e-04, 5.55095612e-04, 5.22839720e-04], [ 4.31689201e-04, 3.79376317e-04, 3.37356236e-04, ..., 6.52617775e-04, 5.69099153e-04, 4.95018496e-04], ... 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]], [[ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], ..., [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00, ..., 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]]]], dtype=float32) - phi(time, lev, lat, lon)float323.119e+03 3.176e+03 ... 2.304e+04
- long_name :
- geopotential_height
- standard_name :
- phi_grid
array([[[[ 3119.1353 , 3176.2488 , 3233.8894 , ..., 2954.6948 , 3007.9807 , 3062.9202 ], [ 2614.8088 , 2745.9558 , 2869.6904 , ..., 2193.6082 , 2336.4714 , 2477.6697 ], [ 2979.612 , 3182.408 , 3354.102 , ..., 2222.5193 , 2493.6682 , 2748.378 ], ..., [ 234.68695, 212.8779 , 224.13223, ..., 557.35144, 404.71756, 297.17188], [ 259.2385 , 240.71661, 234.09258, ..., 388.7506 , 333.8738 , 290.3426 ], [ 262.95663, 262.59714, 263.52557, ..., 271.23715, 267.37503, 264.5746 ]], [[ 4049.0771 , 4104.82 , 4161.079 , ..., 3888.5974 , 3940.5972 , 3994.2134 ], [ 3557.478 , 3685.4272 , 3806.1104 , ..., 3146.3257 , 3285.8154 , 3423.6453 ], [ 3919.9248 , 4117.676 , 4284.959 , ..., 3180.7798 , 3445.624 , 3694.295 ], ... [15432.601 , 15417.584 , 15427.159 , ..., 15672.593 , 15558.201 , 15478.276 ], [15403.821 , 15390.654 , 15386.138 , ..., 15497.8125 , 15457.815 , 15426.227 ], [15363.595 , 15363.392 , 15363.978 , ..., 15368.599 , 15366.265 , 15364.568 ]], [[26438.885 , 26486.312 , 26534.125 , ..., 26302.152 , 26346.479 , 26392.164 ], [26051.504 , 26162.398 , 26267.15 , ..., 25697.04 , 25816.928 , 25935.773 ], [26379.59 , 26550.824 , 26696.812 , ..., 25748.45 , 25973.285 , 26185.637 ], ..., [23147.322 , 23123.832 , 23123.846 , ..., 23403.277 , 23285.314 , 23200.035 ], [23076.121 , 23057.904 , 23048.076 , ..., 23183.205 , 23139.2 , 23103.248 ], [23035.809 , 23033.291 , 23031.652 , ..., 23048.223 , 23043.35 , 23039.182 ]]]], dtype=float32) - ps(time, lat, lon)float327.234e+04 7.178e+04 ... 1.023e+05
- long_name :
- surface_air_pressure
- standard_name :
- ps_grid
array([[[ 72335.54 , 71780.41 , 71224.164, ..., 73955.58 , 73427.125, 72885.76 ], [ 77445.484, 76085.695, 74819.66 , ..., 81941.13 , 80393.89 , 78887.43 ], [ 73903.234, 71918.875, 70265.36 , ..., 81686.32 , 78825.15 , 76214.03 ], ..., [103561.05 , 103852.26 , 103691.6 , ..., 99237.88 , 101266.14 , 102714.984], [103696.43 , 103958.77 , 104058.305, ..., 101906.5 , 102659.984, 103262.31 ], [103955.47 , 103967.91 , 103963.266, ..., 103822.95 , 103881.63 , 103926.37 ]], [[ 72316.81 , 71762.1 , 71206.25 , ..., 73935.516, 73407.5 , 72866.59 ], [ 77425.836, 76066.95 , 74801.62 , ..., 81917.85 , 80371.914, 78866.69 ], [ 73884.06 , 71899.01 , 70244.6 , ..., 81667.47 , 78806.52 , 76195.29 ], ... [102232.17 , 102582.98 , 102490.586, ..., 97817.875, 99859.97 , 101339.53 ], [102135.43 , 102411.06 , 102527.77 , ..., 100337.13 , 101087.75 , 101692.93 ], [102236.414, 102249.37 , 102245.73 , ..., 102105.56 , 102163.13 , 102207.31 ]], [[ 71034.51 , 70486.32 , 69937.305, ..., 72636.03 , 72113.3 , 71578.125], [ 76098.81 , 74756.875, 73509.04 , ..., 80545.18 , 79013.414, 77523.47 ], [ 72591.09 , 70634.016, 69007.78 , ..., 80298.37 , 77460.76 , 74875.16 ], ..., [102507.65 , 102815.875, 102675.984, ..., 98178.83 , 100200.1 , 101651.08 ], [102326.37 , 102575.48 , 102664.39 , ..., 100594.47 , 101325.56 , 101908.5 ], [102333.78 , 102338.68 , 102326.9 , ..., 102225.63 , 102275.96 , 102312.55 ]]], dtype=float32)
Note that the dimensions in the dataframe were reordered to follow the conventions typically used in NWP model outputs. This ordering differs from the internal dimension ordering use by the the underlying SPEEDY.90 (state variables).
For convenience, all the state variables in the SPEEDY.90 model can be accessed from python using items getters and setters.
For example, the model latitude and longitude can be accessed as model["lat"] or model["lon"]. Similarly, to update the value of, let’s say, temperature in the grid space, we use: model[t_grid]=new_t_grid_array
A complete description of the state variables that can be accessed through python are listed in this table.
The model grid
Let’s plot the model grid first to visualize the model’s resolution.
[6]:
import cartopy.crs as ccrs
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
from cartopy.feature import OCEAN
fig = plt.figure(figsize=(15, 10))
ax = plt.subplot(projection=ccrs.PlateCarree())
longitude_2D, latitude_2D = np.meshgrid(model["lon"], model["lat"])
ax.set_title("SPEEDY Gaussian grid") # Add title for each subplot.
ax.set_global() # Set global extention
ax.coastlines() # Add coastlines
ax.add_feature(OCEAN) # Add oceans
_ = ax.scatter(
longitude_2D, latitude_2D, s=4, c="red", marker="o", transform=ccrs.PlateCarree()
)
Matplotlib is building the font cache; this may take a moment.
/home/docs/checkouts/readthedocs.org/user_builds/pyspeedy/conda/latest/lib/python3.8/site-packages/cartopy/io/__init__.py:241: DownloadWarning: Downloading: https://naturalearth.s3.amazonaws.com/110m_physical/ne_110m_ocean.zip
warnings.warn(f'Downloading: {url}', DownloadWarning)
/home/docs/checkouts/readthedocs.org/user_builds/pyspeedy/conda/latest/lib/python3.8/site-packages/cartopy/io/__init__.py:241: DownloadWarning: Downloading: https://naturalearth.s3.amazonaws.com/110m_physical/ne_110m_coastline.zip
warnings.warn(f'Downloading: {url}', DownloadWarning)
Now let’s plots some prognostic variables at the surface.
[7]:
from cartopy.util import add_cyclic_point
# The shape of the t_grid field is ['lon', 'lat', 'lev']
# The vertical dimension is sorted in decreasing height.
# That means that the [:,:,0] indicates the highest level, while [:,:,1] indicate the lowest level.
# For the temperature field we will plot the lowest level (surface).
# The shape of the ps_grid is ['lon', 'lat']
variables_to_plot = [
# (model_variable_name, variable long name)
(
"t_grid",
"Temperature",
"[C]",
), # Surface temperature in Kelvin degrees (in the grid space).
("ps_grid", "Pressure", "[hPa]"), # Surface pressure
]
fig, axs = plt.subplots(
2, 1, subplot_kw=dict(projection=ccrs.PlateCarree()), figsize=(10, 8)
)
lon = model["lon"]
lat = model["lat"]
for i, (var, title, units) in enumerate(variables_to_plot):
ax = axs[i]
plt.sca(ax)
ax.set_title(title) # Add title for each subplot.
ax.set_global() # Set global extention
ax.coastlines() # Add coastlines
ax.add_feature(OCEAN) # Add oceans
data_to_plot = model[var]
if var == "t_grid":
# data_to_plot has [lon, lat, lev] dimensions.
data_to_plot = data_to_plot[:, :, -1] # Keep the lowest level
data_to_plot -= 273.15
elif var == "ps_grid":
data_to_plot /= 100
# Copy the longitude=0 degrees data to longitude=360 to have continuous plots
data_to_plot, lon = add_cyclic_point(data_to_plot, coord=model["lon"], axis=0)
lat = model["lat"]
cs = ax.pcolormesh(
lon,
model["lat"],
data_to_plot.T,
transform=ccrs.PlateCarree(),
cmap="jet",
shading="auto",
)
cbar = plt.colorbar(cs, label=f"{title} {units}")
_ = plt.subplots_adjust(wspace=0.05)
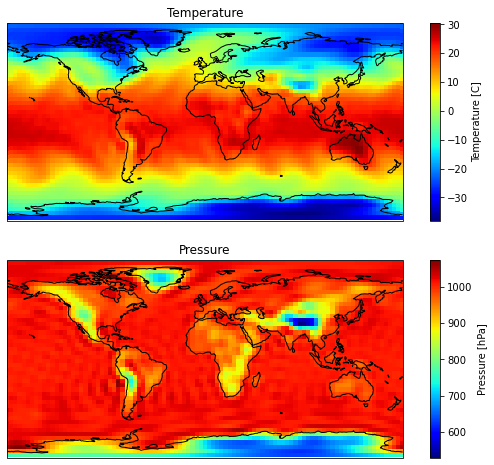
TO BE CONTINUED
[ ]: